5. Carga de datos
En esta sección, usaremos un DataWarehouse virtual y el comando COPY para iniciar la carga masiva de datos estructurados en la tabla Snowflake que creamos en la última sección.
Cambiar el tamaño y usar un DataWarehouse para la carga de datos
Se necesitan recursos informáticos para cargar datos. Los nodos de cómputo de Snowflake se denominan DataWarehouses virtuales y se pueden aumentar o reducir dinámicamente según la carga de trabajo, ya sea que esté cargando datos, ejecutando una consulta o realizando una operación DML. Cada carga de trabajo puede tener su propio DataWarehouse, por lo que no hay contención de recursos.
Vaya a la pestaña DataWarehouses (en Calcular). Aquí es donde puede ver todos sus DataWarehouses existentes, así como analizar sus tendencias de uso.
Tenga en cuenta la opción + DataWarehouse en la esquina superior derecha de la parte superior. Aquí es donde puede agregar rápidamente un nuevo DataWarehouse. Sin embargo, queremos usar el DataWarehouse COMPUTE_WH existente incluido en el entorno de prueba de 30 días.
Haga clic en la fila del DataWarehouse COMPUTE_WH. Luego haga clic en ... (punto, punto, punto) en el texto de la esquina superior derecha para ver las acciones que puede realizar en el DataWarehouse. Usaremos este DataWarehouse para cargar los datos de AWS S3.
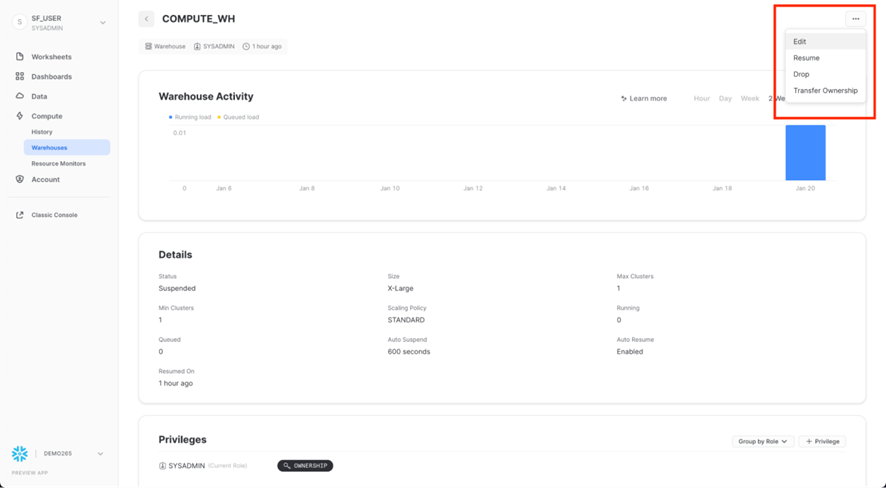
Haga clic en Editar para recorrer las opciones de este DataWarehouse y conocer algunas de las funciones únicas de Snowflake.
Si esta cuenta no usa Snowflake Enterprise Edition (o superior), no verá las opciones Modo o Clústeres que se muestran en la captura de pantalla a continuación. La característica de DataWarehouses de clústeres múltiples no se usa en este laboratorio, pero la discutiremos como una capacidad clave de Snowflake.

- El menú desplegable Tamaño es donde se selecciona la capacidad del DataWarehouse. Para operaciones de carga de datos más grandes o consultas más intensivas en cómputo, se recomienda un DataWarehouse más grande. Los tamaños se traducen en los recursos informáticos subyacentes aprovisionados desde el proveedor de la nube (AWS, Azure o GCP) donde se aloja su cuenta de Snowflake. También determina la cantidad de créditos consumidos por el DataWarehouse por cada hora completa que se ejecuta. Cuanto mayor sea el tamaño, más recursos informáticos del proveedor de la nube se asignan al DataWarehouse y más créditos consume. Por ejemplo, la configuración 4X-Large consume 128 créditos por cada hora completa. Este tamaño se puede cambiar hacia arriba o hacia abajo en cualquier momento con un simple clic.
- Si está utilizando Snowflake Enterprise Edition (o superior) y la opción Multi-cluster Warehouse está habilitada, verá opciones adicionales. Aquí es donde puede configurar un DataWarehouse para utilizar varios clústeres de recursos informáticos, hasta 10 clústeres. Por ejemplo, si a un DataWarehouse de clústeres múltiples 4X-Large se le asigna un tamaño máximo de clúster de 10, puede escalar horizontalmente hasta 10 veces los recursos informáticos que alimentan ese DataWarehouse... ¡y puede hacerlo en segundos! Sin embargo, tenga en cuenta que esto aumentará la cantidad de créditos consumidos por el DataWarehouse a 1280 si los 10 clústeres se ejecutan durante una hora completa (128 créditos/hora x 10 clústeres). El multiclúster es ideal para escenarios de simultaneidad, como muchos analistas comerciales que ejecutan simultáneamente diferentes consultas utilizando el mismo DataWarehouse. En este caso de uso, las diversas consultas se asignan en varios clústeres para garantizar que se ejecuten rápidamente.
- En Opciones avanzadas de DataWarehouse, las opciones le permiten suspender automáticamente el DataWarehouse cuando no está en uso para que no se consuman créditos innecesariamente. También hay una opción para reanudar automáticamente un DataWarehouse suspendido, de modo que cuando se le envía una nueva carga de trabajo, se reinicia automáticamente. Esta funcionalidad habilita el modelo de facturación eficiente de "pague solo por lo que usa" de Snowflake, que le permite escalar sus recursos cuando sea necesario y reducirlos o apagarlos automáticamente cuando no los necesite, eliminando casi por completo los recursos inactivos.
Cómputo de Snowflake frente a otros DataWarehouses de datos Muchas de las capacidades de cómputo y DataWarehouse virtual que acabamos de cubrir, como la capacidad de crear, escalar verticalmente, escalar horizontalmente y suspender/reanudar automáticamente DataWarehouses virtuales, son fáciles de usar en Snowflake y se pueden realizar en segundos. Para los DataWarehouses de datos locales, estas capacidades son mucho más difíciles, si no imposibles, ya que requieren un hardware físico importante, un aprovisionamiento excesivo de hardware para los picos de carga de trabajo y un trabajo de configuración significativo, además de desafíos adicionales. Incluso otros DataWarehouses de datos basados en la nube no pueden escalar hacia arriba y hacia afuera como Snowflake sin mucho más trabajo y tiempo de configuración.
Advertencia - ¡Cuidado con sus gastos! Durante o después de esta práctica de laboratorio, debe tener cuidado al realizar las siguientes acciones sin una buena razón o puede quemar sus $400 de créditos gratuitos más rápido de lo deseado:
No desactive la suspensión automática. Si la suspensión automática está deshabilitada, sus DataWarehouses continúan funcionando y consumiendo créditos incluso cuando no están en uso.
No utilice un tamaño de DataWarehouse que sea excesivo dada la carga de trabajo. Cuanto más grande es el DataWarehouse, más créditos se consumen.
Vamos a utilizar este DataWarehouse virtual para cargar los datos estructurados en los archivos CSV (almacenados en el depósito de AWS S3) en Snowflake. Sin embargo, primero vamos a cambiar el tamaño del DataWarehouse para aumentar los recursos informáticos que utiliza. Después de la carga, anote el tiempo que lleva y luego, en un paso posterior en esta sección, volveremos a hacer la misma operación de carga con un DataWarehouse aún más grande, observando su tiempo de carga más rápido.
Cambie el tamaño de este DataWarehouse de datos de X-Small a Small. luego haga clic en el botón Guardar DataWarehouse:

Cargar los datos
Ahora podemos ejecutar un comando COPY para cargar los datos en la tabla TRIPS que creamos anteriormente.
Vuelva a la hoja de trabajo CITIBIKE_ZERO_TO_SNOWFLAKE en la pestaña Hojas de trabajo. Asegúrese de que el contexto de la hoja de trabajo esté configurado correctamente:
Rol: SYSADMIN DataWarehouse: COMPUTE_WH Base de datos: CITIBIKE Esquema = PÚBLICO

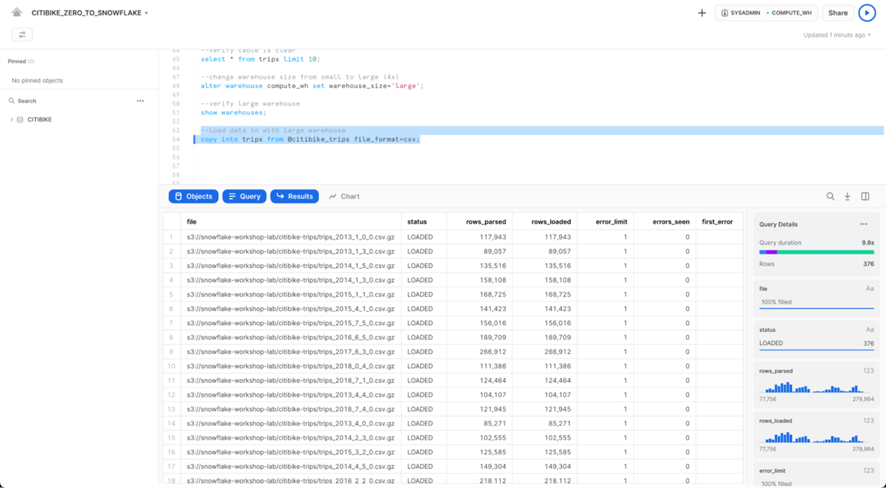
Ejecute las siguientes declaraciones en la hoja de trabajo para cargar los datos por etapas en la tabla. Esto puede tardar hasta 30 segundos.
copy into trips from @citibike_trips file_format=csv PATTERN = '.*csv.*' ;
En el panel de resultados, debería ver el estado de cada archivo que se cargó. Una vez finalizada la carga, en el panel Detalles de la consulta en la parte inferior derecha, puede desplazarse por los distintos estados, estadísticas de error y visualizaciones de la última instrucción ejecutada:
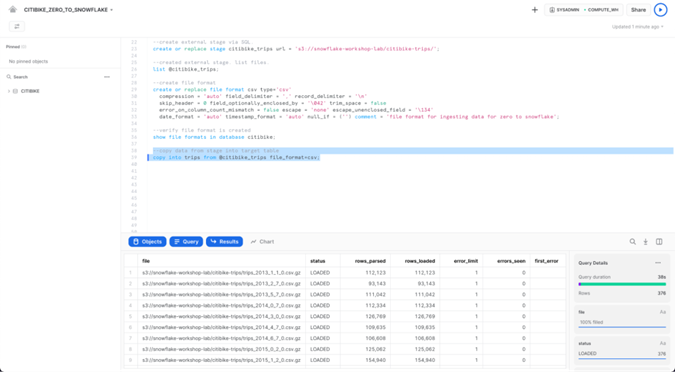
A continuación, navegue a la pestaña Historial haciendo clic en el ícono Inicio y luego Compute > History. Seleccione la consulta en la parte superior de la lista, que debe ser la instrucción COPY INTO que se ejecutó por última vez. Tenga en cuenta los pasos que tomó la consulta para ejecutarse, los detalles de la consulta, los nodos más caros y las estadísticas adicionales.
Ahora volvamos a cargar la tabla TRIPS con un DataWarehouse más grande para ver el impacto que tienen los recursos informáticos adicionales en el tiempo de carga.
Regrese a la hoja de trabajo y use el comando TRUNCATE TABLE para borrar la tabla de todos los datos y metadatos:
truncate table trips;
Verifique que la tabla esté vacía ejecutando el siguiente comando:
--verify table is clear
select * from trips limit 10;
El resultado debería mostrar "La consulta no produjo resultados".
Cambie el tamaño del DataWarehouse a grande usando el siguiente ALTER WAREHOUSE:
--change warehouse size from small to large (4x)
alter warehouse compute_wh set warehouse_size='large';
Verifique el cambio utilizando los siguientes DATAWAREHOUSES DE MUESTRA:
--load data with large warehouse
show warehouses;
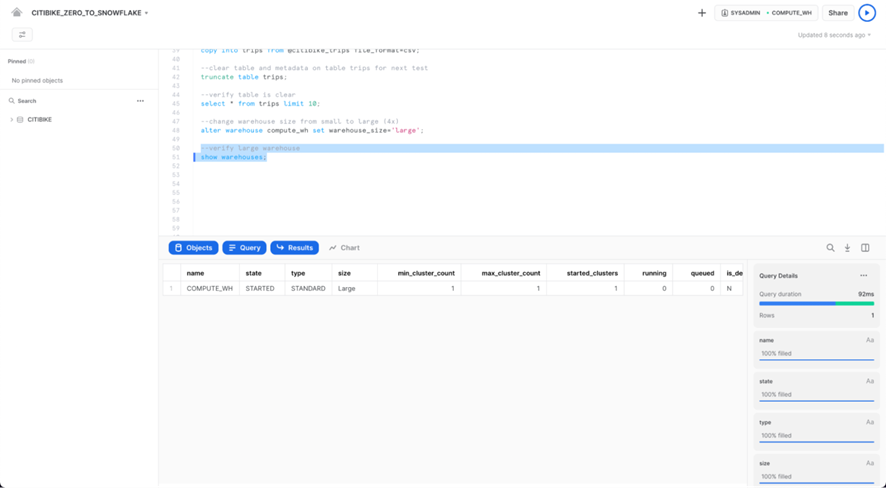
El tamaño también se puede cambiar usando la interfaz de usuario haciendo clic en el cuadro de contexto de la hoja de trabajo, luego en el ícono Configurar (3 líneas) en el lado derecho del cuadro de contexto y cambiando Pequeño a Grande en el menú desplegable Tamaño:


Ejecute la misma instrucción COPY INTO que antes para volver a cargar los mismos datos:
copy into trips from @citibike_trips
file_format=CSV;
Una vez finalizada la carga, navegue de nuevo a la página Consultas (icono de inicio > Cómputo > Historial > Consultas). Compare los tiempos de los dos comandos COPY INTO. La carga utilizando el DataWarehouse grande fue significativamente más rápida.
Crear un nuevo DataWarehouse para análisis de datos
Volviendo a la historia del laboratorio, supongamos que el equipo de Citi Bike quiere eliminar la contención de recursos entre sus cargas de trabajo de carga de datos/ETL y los usuarios finales analíticos que usan herramientas de BI para consultar Snowflake. Como se mencionó anteriormente, Snowflake puede hacer esto fácilmente al asignar diferentes DataWarehouses de tamaño adecuado a varias cargas de trabajo. Dado que Citi Bike ya tiene un DataWarehouse para la carga de datos, creemos un nuevo DataWarehouse para los usuarios finales que ejecutan análisis. Usaremos este DataWarehouse para realizar análisis en la siguiente sección.
Vaya a la pestaña Calcular > DataWarehouses, haga clic en + DataWarehouse y asigne al nuevo DataWarehouse el nombre ANALYTICS_WH y establezca el tamaño en Grande.
Si está utilizando Snowflake Enterprise Edition (o superior) y los DataWarehouses multiclúster están habilitados, verá configuraciones adicionales:
- Asegúrese de que Max Clusters esté establecido en 1.
- Deje todas las demás configuraciones en sus valores predeterminados.
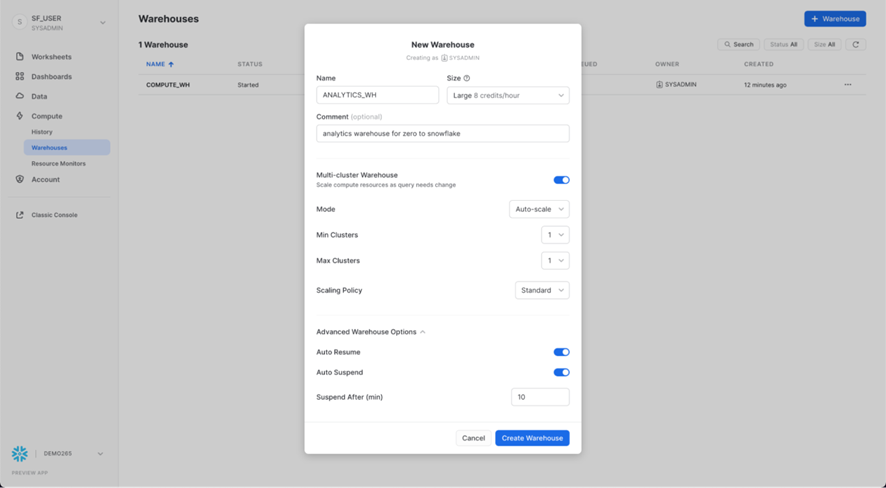
Haga clic en el botón Crear DataWarehouse para crear el DataWarehouse.











