6. Trabajando con Queries, los resultados en Cache y Cloning
En los ejercicios anteriores, cargamos datos en dos tablas usando el comando de cargador masivo COPY de Snowflake y el DataWarehouse virtual COMPUTE_WH. Ahora vamos a asumir el rol de los usuarios de análisis en Citi Bike que necesitan consultar datos en esas tablas usando la hoja de trabajo y el segundo DataWarehouse ANALYTICS_WH.
Roles y consultas del mundo real Dentro de una empresa real, los usuarios de análisis probablemente tendrían un rol diferente al de SYSADMIN. Para simplificar la práctica de laboratorio, nos quedaremos con la función SYSADMIN para esta sección. Además, las consultas normalmente se realizan con un producto de inteligencia comercial como Tableau, Looker, PowerBI, etc. Para análisis más avanzados, las herramientas de ciencia de datos como Datarobot, Dataiku, AWS Sagemaker y muchas otras pueden consultar a Snowflake. Cualquier tecnología que aproveche JDBC/ODBC, Spark, Python o cualquiera de las otras interfaces programáticas admitidas puede ejecutar análisis de los datos en Snowflake. Para simplificar este laboratorio, todas las consultas se ejecutan a través de la hoja de trabajo de Snowflake.
Ejecutar algunas consultas
Vaya a la hoja de trabajo CITIBIKE_ZERO_TO_SNOWFLAKE y cambie el DataWarehouse para usar el nuevo DataWarehouse que creó en la última sección. El contexto de su hoja de trabajo debe ser el siguiente:
Rol: SYSADMIN DataWarehouse: ANALYTICS_WH (L) Base de datos: CITIBIKE Esquema = PÚBLICO

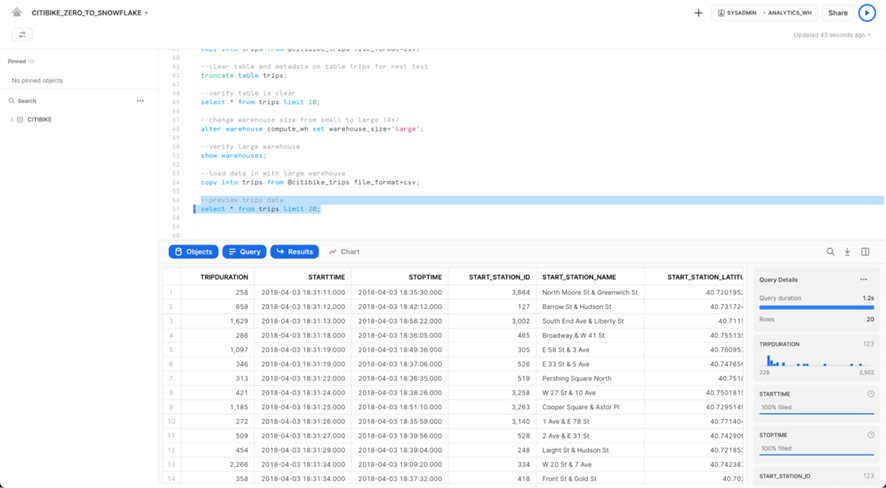
Ejecute la siguiente consulta para ver una muestra de los datos de viajes:
select * from trips limit 20;
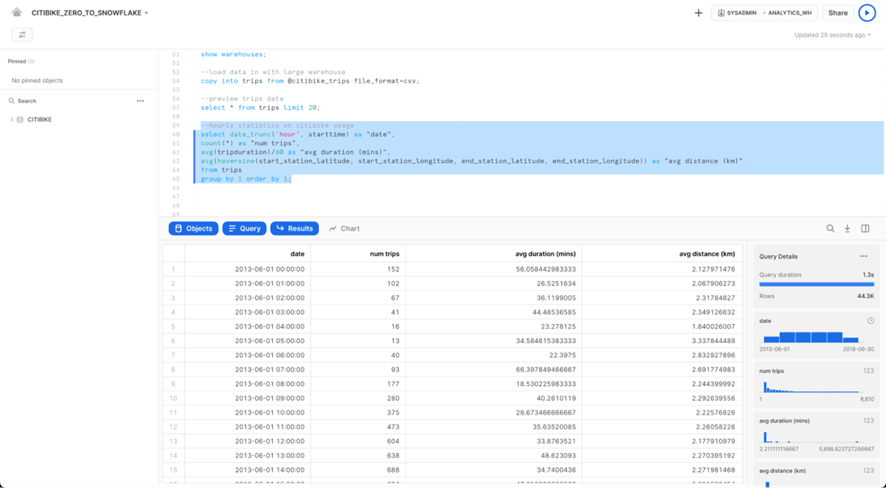
Ahora, veamos algunas estadísticas básicas por hora sobre el uso de Citi Bike. Ejecute la consulta a continuación en la hoja de trabajo. Para cada hora, muestra el número de viajes, la duración promedio del viaje y la distancia promedio del viaje.
select date_trunc('hour', starttime) as "date",
count(*) as "num trips",
avg(tripduration)/60 as "avg duration (mins)",
avg(haversine(start_station_latitude, start_station_longitude, end_station_latitude,
end_station_longitude)) as "avg distance (km)"
from trips
group by 1 order by 1;
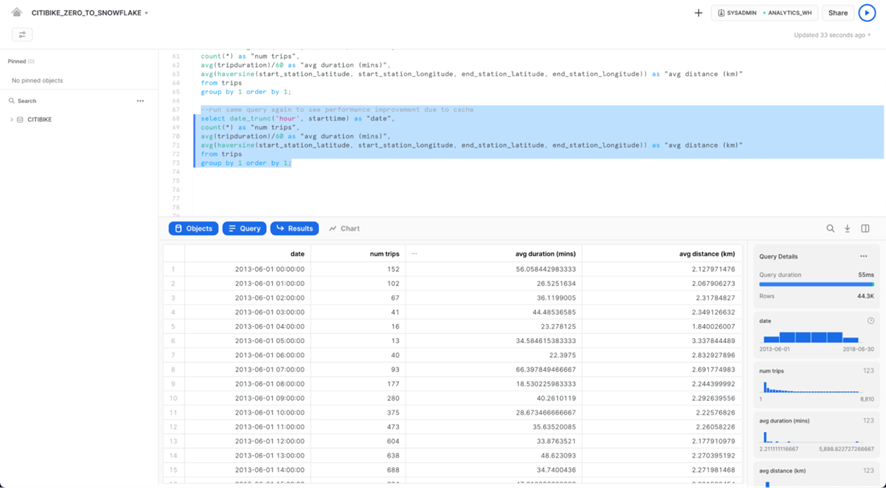
Usar la caché de resultados
Snowflake tiene un caché de resultados que contiene los resultados de cada consulta ejecutada en las últimas 24 horas. Estos están disponibles en todos los DataWarehouses, por lo que los resultados de la consulta devueltos a un usuario están disponibles para cualquier otro usuario en el sistema que ejecute la misma consulta, siempre que los datos subyacentes no hayan cambiado. Estas consultas repetidas no solo regresan extremadamente rápido, sino que tampoco usan créditos de cómputo.
Veamos la memoria caché de resultados en acción ejecutando exactamente la misma consulta nuevamente.
select date_trunc('hour', starttime) as "date",
count(*) as "num trips",
avg(tripduration)/60 as "avg duration (mins)",
avg(haversine(start_station_latitude, start_station_longitude, end_station_latitude,
end_station_longitude)) as "avg distance (km)"
from trips
group by 1 order by 1;
En el panel Detalles de la consulta de la derecha, tenga en cuenta que la segunda consulta se ejecuta significativamente más rápido porque los resultados se han almacenado en caché.
Ejecutar otra consulta
A continuación, ejecutemos la siguiente consulta para ver qué meses son los más ocupados:
selectmonthname(starttime) as "month",count(*) as "num trips"from tripsgroup by 1 order by 2 desc;
Clonar una tabla
Snowflake le permite crear clones, también conocidos como "clones de copia cero" de tablas, esquemas y bases de datos en segundos. Cuando se crea un clon, Snowflake toma una instantánea de los datos presentes en el objeto de origen y los pone a disposición del objeto clonado. El objeto clonado es escribible e independiente de la fuente de clonación. Por lo tanto, los cambios realizados en el objeto de origen o en el objeto de clonación no se incluyen en el otro.
Un caso de uso popular para la clonación sin copia es clonar un entorno de producción para que lo utilicen los equipos de desarrollo y pruebas para probar y experimentar sin afectar negativamente al entorno de producción y eliminando la necesidad de configurar y administrar dos entornos separados.
Clonación de copia cero Una gran ventaja de la clonación de copia cero es que los datos subyacentes no se copian. Solo cambian los metadatos y los punteros a los datos subyacentes. Por lo tanto, los clones son "copia cero" y los requisitos de almacenamiento no se duplican cuando se clonan los datos. La mayoría de los DataWarehouses de datos no pueden hacer esto, ¡pero para Snowflake es fácil!
Ejecute el siguiente comando en la hoja de trabajo para crear un clon de tabla de desarrollo (dev) de la tabla de viajes:
create table trips_dev clone trips;
Haga clic en los tres puntos (...) en el panel izquierdo y seleccione Actualizar. Expanda el árbol de objetos debajo de la base de datos de CITIBIKE y verifique que vea una nueva tabla llamada trips_dev. Su equipo de desarrollo ahora puede hacer lo que quiera con esta tabla, incluso actualizarla o eliminarla, sin afectar la tabla de viajes ni ningún otro objeto.












